OpenAI GPT 5.2 breekt benchmarks en toont grote sprong in redeneren
Nieuwsdonderdag, 11 december 2025 om 20:05
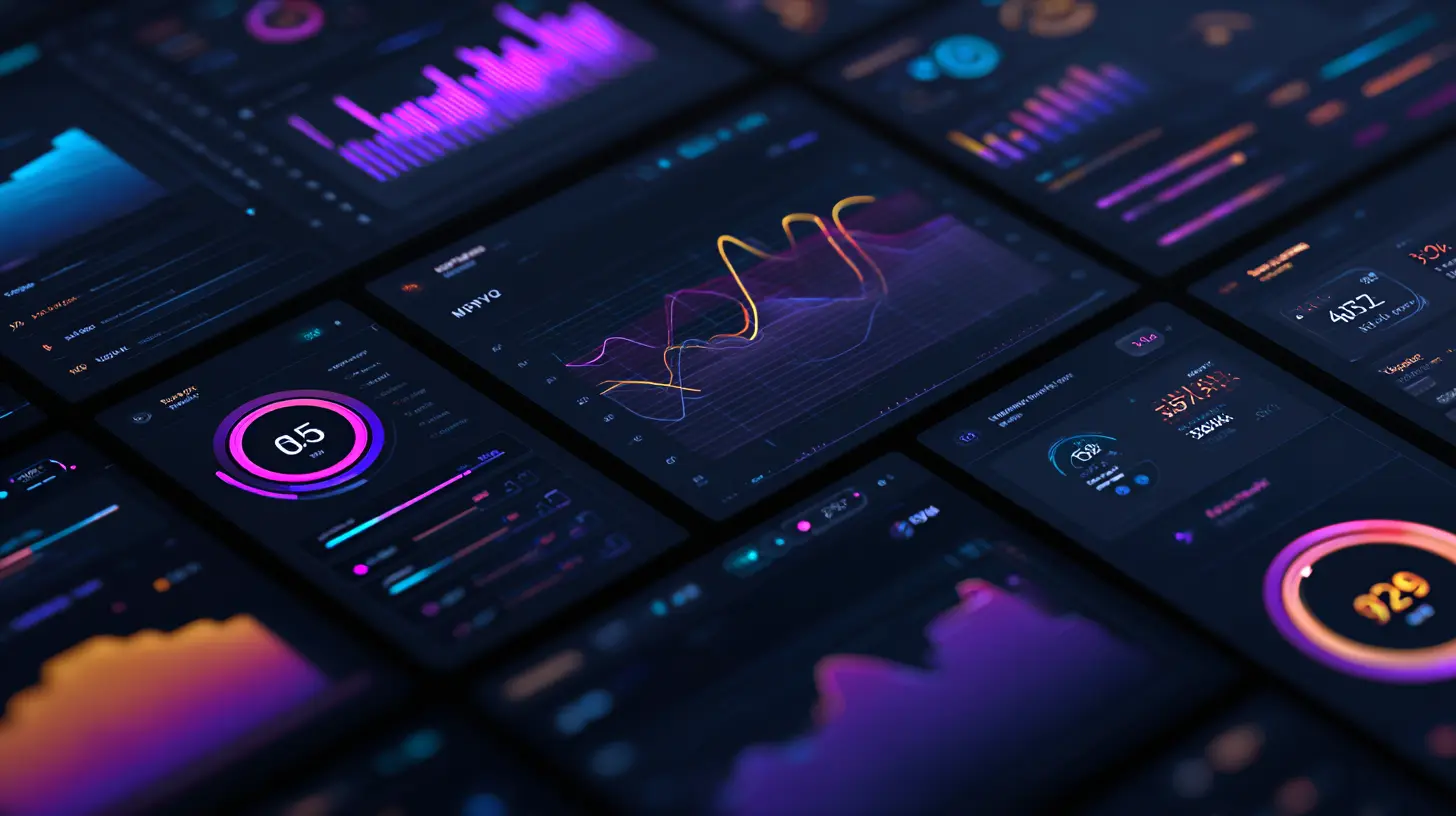
OpenAI presenteert nieuwe benchmarkresultaten voor GPT 5.2 Thinking. De grafiek laat zien dat het model op vrijwel alle redeneer- en wiskundetests aanzienlijk beter scoort dan GPT 5.1 en concurrerende modellen zoals Claude Opus 4.5 en Google Gemini 3 Pro.
Deze sprong suggereert dat OpenAI opnieuw de leiding neemt op het gebied van diepe redenering, abstracte logica en complexe probleemoplossing binnen kunstmatige intelligentie.
Wat zien we precies in de tabel?
De afbeelding toont een reeks gestandaardiseerde AI-tests die verschillende cognitieve vaardigheden meten. Elke rij vertegenwoordigt een benchmark. Elk kolom toont de score van een specifiek AI-model.

De opvallendste resultaten:
- SWE-Bench Pro (software engineering). GPT 5.2 scoort 55,6 procent, wat hoger is dan GPT 5.1 en de concurrentie. Dit wijst op sterk verbeterde code-analyse en foutoplossing.
- GPQA Diamond (wetenschappelijke vragen). GPT 5.2 behaalt 92,4 procent en overtreft daarmee zowel Claude Opus 4.5 als Gemini 3 Pro.
- CharXiv Reasoning (wetenschappelijke figuren interpreteren). GPT 5.2 staat op 82,1 procent. Dit toont aan dat het model complexe grafieken en diagrammen veel beter begrijpt dan eerdere generaties.
- FrontierMath (geavanceerde wiskunde). Hier zien we een spanningsveld. GPT 5.2 scoort 40,3 procent op Tier 1-3 en 14,6 procent op Tier 4. Hoewel hoger dan GPT 5.1, blijft dit gebied uitdagend voor alle modellen.
- AIME 2025 (competitiewiskunde zonder hulpmiddelen). GPT 5.2 haalt 100 procent en laat hiermee een indrukwekkende stap zien richting menselijke competitieprestaties.
- ARC-AGI (abstracte redeneeropdrachten). GPT 5.2 scoort 86,2 procent op versie 1 en 52,9 procent op versie 2. Hiermee ligt het model ver boven GPT 5.1 en de meeste concurrenten.
- GDPval (algemene werkgerelateerde taken). GPT 5.2 komt uit op 70,9 procent, een duidelijke verbetering vergeleken met GPT 5.1.
Wat betekent dit voor GPT 5.2?
Deze resultaten laten zien dat GPT 5.2 een grotere stap vooruit is dan de overgang van GPT 4 naar GPT 5. Vooral de categorieën wetenschappelijke redenering, competitiewiskunde en abstracte intelligentie springen eruit. GPT 5.2 gedraagt zich meer als een systeem dat langdurige redeneringsketens begrijpt in plaats van enkel losse patronen te herkennen.
Voor ontwikkelaars betekent dit dat GPT 5.2 beter kan:
- complexe codebases analyseren;
- wetenschappelijke papers interpreteren;
- logische puzzels oplossen zonder hulpmiddelen;
- wiskundige problemen doorrekenen met hogere nauwkeurigheid;
- zakelijke beslissingsondersteuning bieden op basis van meerdere variabelen.
Voor gebruikers betekent het dat de modeloutput betrouwbaarder, consistenter en dieper onderbouwd is, vooral bij technisch of abstract werk.
Lees ook



Hoe verhoudt GPT 5.2 zich tot concurrenten?
De grafiek toont dat Claude Opus 4.5 en Gemini 3 Pro op sommige vlakken competitief zijn, vooral op GPQA en AIME. Toch haalt geen van beide modellen dezelfde balans tussen wiskunde, logica, software engineering en wetenschappelijke interpretatie.
GPT 5.2 lijkt zich te profileren als het eerste model dat richting generalist reasoning beweegt. Eén systeem dat meerdere hoogcomplexe domeinen tegelijk goed beheerst.

Robin HeesterOprichter
Robin Heester is mede-oprichter van AI Wereld en heeft door de jaren heen meerdere websites, nieuwsbrieven en magazines opgericht. Hij schrijft over technologie, innovatie en de maatschappelijke impact van nieuwe digitale ontwikkelingen.
Populair nieuws

Is Apple Intelligence gratis? Prijs, iCloud+ en gebruikslimieten uitgelegd

Wat is Apple Intelligence? Complete uitleg over functies, apparaten, Siri AI en privacy

Apple Intelligence in Nederland: Nederlands, beschikbaarheid en EU-beperkingen

Welke apparaten ondersteunen Apple Intelligence? Geschikte iPhones, iPads en Macs

Is Apple Intelligence veilig? Privacy en Private Cloud Compute uitgelegd
Laatste reacties
- Wie wordt er beter van.....zal Meta wel zijnhenk.h10-07-2026
- Wat voor weer wordt het vandaaghenk.h03-07-2026
- Dit artikel is van 1 april, dus deze belasting is niet echt. Gelukkig maar. :)RobinHeester12-05-2026
- Of een ander land..dat lijkt mij beterHan10-05-2026
- Op 1 april 2028 komt er een AI die al het kantoorwerk van alle Nederlanders overneemt. Heb ik van horen zeggen.RobinHeester01-04-2026
- AI moet een tool zijn. Maar net als Excel, je e-mailbox of Photoshop: die tool kan steeds meer voor je doen als je het de juiste input geeft. Dat ligt bij dokters en andere soortgelijke zaken wel wat gevoeliger. ;)RobinHeester01-04-2026
- Er komt ook extra inkomsten belasting op mensen die met ai hun geld verdienen. De maarregel gaat in op 1 aprill 2027. Er is nog een jaar om een andere baan te vinden.max01-04-2026
- Als ik dit lees moet ik terugdenken aan de tijd, dat ik als IT specialist, dat woord bestond toen nog niet, een programma schreef om de de maagontlediging te meten met een gamma camera.de patient eet een radioactieve pannekoek en eet die op. Je zet de patiënt voor een gammacamera die de verplaatsing van de radioactieviteit in de patient meet. Daar rolt een cijfer uit. De arts die naast mij zat om de uitkomst van de meeting te evalueren zat naast met en zei. Dat is mooi de computer heeft het berekend en die maakt géén fouten. Ik ben bang dat de jonge artsen van nu op AI gaan vertrouwen want die begrijpen niets van hoe AI tot de diagnose komt. Hun ervaring met AI en de patiënten is beide heel miniium. Voordat je met AI gaat werken moet je helaas goed beseffen dat AI fouten maakt, maar vaak zo praat of schrijft dat het een waarheid als een koe is. Een eenvoudige systeem prompt "Als je het niet weet zeg dan gewoon: ik weet het niet niet." Bracht een ai systeem zodanig in de war dat er geen antwoord meer kwam. Het systeem moest van zichzelf altijd antwoord geven. Jonge medicie moeten zich er terdege van bewust zijn dat je boven de stof moet staan en dan pas AI als ondersteuning mag gebruiken bij de diagnose voor echte mensen.max31-03-2026
- Heel veel modems doen dat als voorbeeld het ASUS TUF Gaming AX6000 modem dat staat gewoon in de voorwaarden. Wel kun je dat vermijden met Open-wrt te draaien.max13-03-2026
- fascinerend hoe juist bij Martin (die tegen AI in de rechtszaal staat) de verdenking opduikt.. dat ondermijnt vertrouwen op twee fronten.ai_arjanb11-11-2025
Loading