Nieuw onderzoek presenteert snelle responsstrategie tegen AI-jailbreaks
Nieuwswoensdag, 13 november 2024 om 22:55

Onderzoekers hebben een nieuwe aanpak ontwikkeld om large language models (LLMs) te beschermen tegen zogeheten jailbreaks, waarbij AI-systemen worden misbruikt voor ongeautoriseerde of schadelijke acties. Het onderzoek richt zich op een snelle respons in plaats van het streven naar onfeilbare beveiliging. De resultaten, gepubliceerd door een team van onderzoekers, tonen aan dat snel reageren op nieuwe aanvalsmethoden een effectieve manier kan zijn om AI-misbruik te beperken.
Snelle respons in plaats van perfecte beveiliging
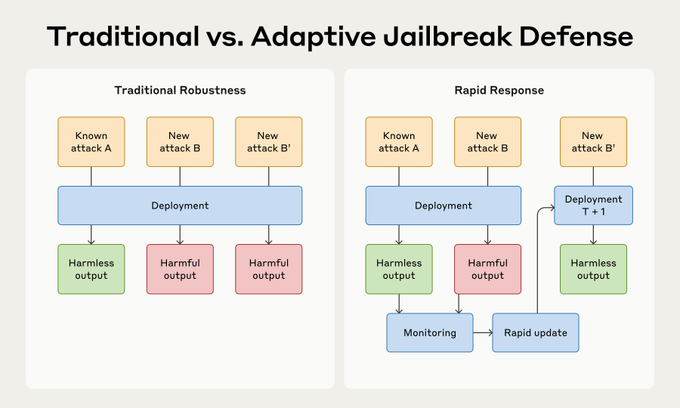
Het onderzoek introduceert een strategie waarbij in plaats van te streven naar volledige bescherming tegen alle mogelijke aanvallen, wordt gefocust op een "rapid response"-aanpak. Deze aanpak houdt in dat zodra een nieuwe jailbreak wordt gedetecteerd, snel een methode wordt ontwikkeld om deze te blokkeren. De studie benadrukt dat het mogelijk is om hele klassen van jailbreaks te neutraliseren na het observeren van slechts enkele voorbeelden.
De introductie van RapidResponseBench
Om deze benadering te testen, ontwikkelden de onderzoekers een speciaal benchmark-systeem genaamd RapidResponseBench. Dit systeem meet hoe goed een verdedigingsstrategie zich aanpast aan verschillende jailbreaktechnieken na het observeren van een beperkt aantal voorbeelden. De kern van deze methode is jailbreak-proliferatie, waarbij nieuwe jailbreaks automatisch worden gegenereerd op basis van de waargenomen voorbeelden.
Belangrijke resultaten en methoden
Uit de studie bleek dat het fine-tunen van een input-classificator het meest effectief was. Deze classificator blokkeert prolifererende jailbreaks door zich aan te passen aan nieuwe aanvalspatronen. De onderzoekers rapporteerden dat deze methode de succesratio van aanvallen met een factor van meer dan 240 keer verminderde bij in-distributie-aanvallen en met een factor van meer dan 15 keer bij uit-distributie-aanvallen, en dit na slechts één waargenomen voorbeeld van elke aanvalstechniek.
Lees ook


Wie zijn de onderzoekers?
Dit onderzoek is uitgevoerd door een team bestaande uit Alwin Peng, Julian Michael, Henry Sleight, Ethan Perez en Mrinank Sharma. Zij stelden vast dat zowel de kwaliteit van het proliferatiemodel als het aantal gegenereerde voorbeelden cruciaal zijn voor de effectiviteit van deze snelle responsstrategie.
Betekenis voor de toekomst van AI-beveiliging
Naarmate LLM’s, zoals die van OpenAI en andere techbedrijven, steeds geavanceerder worden, neemt ook het risico op misbruik toe. AI-jailbreaks kunnen ertoe leiden dat modellen schadelijke of ongepaste inhoud genereren, wat zowel veiligheids- als ethische problemen kan veroorzaken. Deze nieuwe aanpak biedt een veelbelovende strategie om AI-systemen beter te beschermen zonder afhankelijk te zijn van onfeilbare beveiligingsmaatregelen.
Met deze nieuwe bevindingen zetten de onderzoekers een stap voorwaarts in het verdedigen van AI-systemen tegen misbruik. De snelle responsstrategie kan een cruciale rol spelen in de voortdurende ontwikkeling van veiligere en betrouwbaardere AI-modellen in een steeds complexere digitale wereld.

Robin HeesterOprichter
Robin Heester is mede-oprichter van AI Wereld en heeft door de jaren heen meerdere websites, nieuwsbrieven en magazines opgericht. Hij schrijft over technologie, innovatie en de maatschappelijke impact van nieuwe digitale ontwikkelingen.
Populair nieuws

AI-beurs bereikt nieuwe mijlpaal: Nvidia boven 5 biljoen dollar, IBM verrast Wall Street met winstwaarschuwing

Wat kan Claude? De belangrijkste functies uitgelegd

Claude Code: complete handleiding voor installatie, functies en veilig gebruik

Google DeepMind wil nieuwe AI-waakhond, met de VS als leider

Claude Design gebruiken: complete uitleg en handleiding

OpenAI: complete uitleg over het bedrijf achter ChatGPT
Laatste reacties
- Wie wordt er beter van.....zal Meta wel zijnhenk.h10-07-2026
- Wat voor weer wordt het vandaaghenk.h03-07-2026
- Dit artikel is van 1 april, dus deze belasting is niet echt. Gelukkig maar. :)RobinHeester12-05-2026
- Of een ander land..dat lijkt mij beterHan10-05-2026
- Op 1 april 2028 komt er een AI die al het kantoorwerk van alle Nederlanders overneemt. Heb ik van horen zeggen.RobinHeester01-04-2026
- AI moet een tool zijn. Maar net als Excel, je e-mailbox of Photoshop: die tool kan steeds meer voor je doen als je het de juiste input geeft. Dat ligt bij dokters en andere soortgelijke zaken wel wat gevoeliger. ;)RobinHeester01-04-2026
- Er komt ook extra inkomsten belasting op mensen die met ai hun geld verdienen. De maarregel gaat in op 1 aprill 2027. Er is nog een jaar om een andere baan te vinden.max01-04-2026
- Als ik dit lees moet ik terugdenken aan de tijd, dat ik als IT specialist, dat woord bestond toen nog niet, een programma schreef om de de maagontlediging te meten met een gamma camera.de patient eet een radioactieve pannekoek en eet die op. Je zet de patiënt voor een gammacamera die de verplaatsing van de radioactieviteit in de patient meet. Daar rolt een cijfer uit. De arts die naast mij zat om de uitkomst van de meeting te evalueren zat naast met en zei. Dat is mooi de computer heeft het berekend en die maakt géén fouten. Ik ben bang dat de jonge artsen van nu op AI gaan vertrouwen want die begrijpen niets van hoe AI tot de diagnose komt. Hun ervaring met AI en de patiënten is beide heel miniium. Voordat je met AI gaat werken moet je helaas goed beseffen dat AI fouten maakt, maar vaak zo praat of schrijft dat het een waarheid als een koe is. Een eenvoudige systeem prompt "Als je het niet weet zeg dan gewoon: ik weet het niet niet." Bracht een ai systeem zodanig in de war dat er geen antwoord meer kwam. Het systeem moest van zichzelf altijd antwoord geven. Jonge medicie moeten zich er terdege van bewust zijn dat je boven de stof moet staan en dan pas AI als ondersteuning mag gebruiken bij de diagnose voor echte mensen.max31-03-2026
- Heel veel modems doen dat als voorbeeld het ASUS TUF Gaming AX6000 modem dat staat gewoon in de voorwaarden. Wel kun je dat vermijden met Open-wrt te draaien.max13-03-2026
- fascinerend hoe juist bij Martin (die tegen AI in de rechtszaal staat) de verdenking opduikt.. dat ondermijnt vertrouwen op twee fronten.ai_arjanb11-11-2025
Loading