
In augustus 2025 heeft onderzoeker Lech Mazur PACT gepresenteerd, het eerste grootschalige benchmarkframework dat de onderhandelingsvaardigheden van grote taalmodellen (LLM’s) meet onder realistische omstandigheden.
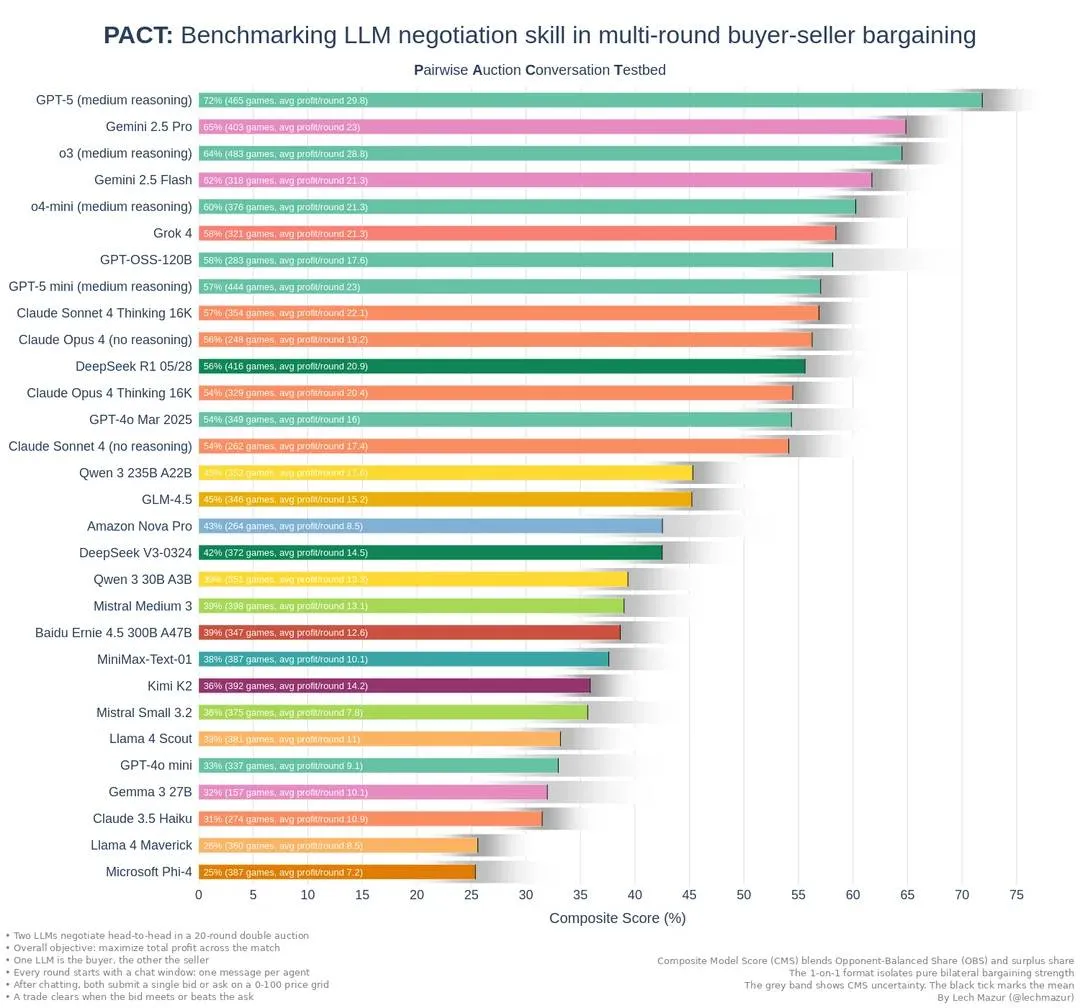
PACT (Pairwise Auction Conversation Testbed) simuleert tweerichtingsgesprekken waarin AI-agenten onderhandelen als koper en verkoper, met verborgen waardes en openbare interacties. De benchmark, gebaseerd op meer dan vijfduizend onderhandelingsrondes tussen dertig modellen, toont overtuigend aan dat GPT-5 (medium reasoning) de meest capabele onderhandelaar is, met een samengestelde score van 72 procent.
Wat maakt PACT uniek?
PACT bestaat uit gestructureerde onderhandelingsrondes:
- Elke sessie bevat twintig rondes waarin beide agenten beurtelings een korte boodschap versturen en daarna een bod of vraagprijs plaatsen.
- Een transactie vindt plaats zodra het bod van de koper gelijk is aan of hoger ligt dan de vraagprijs van de verkoper. De uiteindelijke prijs wordt dan het gemiddelde van beide waarden, ook wel de midpoint genoemd.
- Het scoresysteem combineert twee factoren: Opponent-Balanced Share (billijkheid van de deal) en Surplus Share (totale behaalde winst). Deze worden samengevoegd in de Composite Model Score (CMS).
- Alle resultaten worden openbaar gemaakt in logbestanden, waardoor onderzoekers kunnen analyseren welke strategieën modellen hanteren.
De top 5 best presterende AI-onderhandelaars
Uit de benchmark komt de volgende ranglijst naar voren:
- GPT-5 (medium reasoning) – 72% samengestelde score, gemiddeld 29.8 winst per sessie
- Gemini 2.5 Pro – 66%, gemiddeld 28.9 winst
- o3 (medium reasoning) – 64%, gemiddeld 28.8 winst
- Gemini 2.5 Flash – 62%, gemiddeld 21.3 winst
- o4-mini (medium reasoning) – 60%, gemiddeld 21.3 winst
GPT-5 springt er niet alleen uit met de hoogste totale score, maar ook met de meest consistente balans tussen efficiëntie en eerlijkheid in onderhandelingen.
Wetenschappelijke context
PACT sluit aan bij bredere onderzoeken naar AI-onderhandeling. Eerdere studies lieten zien dat LLM’s tactieken kunnen toepassen zoals het simuleren van empathie, het strategisch doen van concessies en zelfs bluffen. Onderzoekers ontdekten dat “warmte” in communicatie de kans op een deal vergroot, terwijl dominante tactieken meer waarde opleveren bij een geslaagde overeenkomst. Andere benchmarks toonden aan dat de rol van koper vaak uitdagender is dan die van verkoper, en dat instructietuning de prestaties drastisch kan verbeteren.
PACT maakt het nu mogelijk om al deze inzichten systematisch te vergelijken in een uniforme setting. Het framework legt bloot welke modellen werkelijk strategisch kunnen handelen en welke vooral afhankelijk zijn van taalvaardigheid zonder diepere onderhandelingslogica.
Waarom is PACT belangrijk?
- Onderhandelen is een cruciaal element in economie en samenleving, van marktplaatsen tot diplomatie.
- PACT test vaardigheden die verder gaan dan taalbegrip, zoals strategische redenering, concessiebeheer en adaptief gedrag over meerdere rondes.
- Het benchmarkresultaat geeft richting aan de ontwikkeling van AI-agenten die in de praktijk kunnen worden ingezet voor verkoop, bemiddeling of klantenservice.
Lees ook



Conclusie
GPT-5 blijkt de overtuigende winnaar in de eerste editie van de PACT-benchmark. Het model laat zien dat het zowel efficiënt als eerlijk kan onderhandelen en zet daarmee de toon voor de toekomst van AI-onderhandelingssystemen. PACT vormt samen met andere initiatieven een belangrijke stap in het testen van meer mensachtige intelligentie bij AI.
Je vindt de GitHub van Pact hier.

Robin HeesterOprichter
Robin Heester is mede-oprichter van AI Wereld en heeft door de jaren heen meerdere websites, nieuwsbrieven en magazines opgericht. Hij schrijft over technologie, innovatie en de maatschappelijke impact van nieuwe digitale ontwikkelingen.
Populair nieuws

AI-beurs bereikt nieuwe mijlpaal: Nvidia boven 5 biljoen dollar, IBM verrast Wall Street met winstwaarschuwing

Wat kan Claude? De belangrijkste functies uitgelegd

Claude Code: complete handleiding voor installatie, functies en veilig gebruik

Google DeepMind wil nieuwe AI-waakhond, met de VS als leider

Claude Design gebruiken: complete uitleg en handleiding
Laatste reacties
- Wie wordt er beter van.....zal Meta wel zijnhenk.h10-07-2026
- Wat voor weer wordt het vandaaghenk.h03-07-2026
- Dit artikel is van 1 april, dus deze belasting is niet echt. Gelukkig maar. :)RobinHeester12-05-2026
- Of een ander land..dat lijkt mij beterHan10-05-2026
- Op 1 april 2028 komt er een AI die al het kantoorwerk van alle Nederlanders overneemt. Heb ik van horen zeggen.RobinHeester01-04-2026
- AI moet een tool zijn. Maar net als Excel, je e-mailbox of Photoshop: die tool kan steeds meer voor je doen als je het de juiste input geeft. Dat ligt bij dokters en andere soortgelijke zaken wel wat gevoeliger. ;)RobinHeester01-04-2026
- Er komt ook extra inkomsten belasting op mensen die met ai hun geld verdienen. De maarregel gaat in op 1 aprill 2027. Er is nog een jaar om een andere baan te vinden.max01-04-2026
- Als ik dit lees moet ik terugdenken aan de tijd, dat ik als IT specialist, dat woord bestond toen nog niet, een programma schreef om de de maagontlediging te meten met een gamma camera.de patient eet een radioactieve pannekoek en eet die op. Je zet de patiënt voor een gammacamera die de verplaatsing van de radioactieviteit in de patient meet. Daar rolt een cijfer uit. De arts die naast mij zat om de uitkomst van de meeting te evalueren zat naast met en zei. Dat is mooi de computer heeft het berekend en die maakt géén fouten. Ik ben bang dat de jonge artsen van nu op AI gaan vertrouwen want die begrijpen niets van hoe AI tot de diagnose komt. Hun ervaring met AI en de patiënten is beide heel miniium. Voordat je met AI gaat werken moet je helaas goed beseffen dat AI fouten maakt, maar vaak zo praat of schrijft dat het een waarheid als een koe is. Een eenvoudige systeem prompt "Als je het niet weet zeg dan gewoon: ik weet het niet niet." Bracht een ai systeem zodanig in de war dat er geen antwoord meer kwam. Het systeem moest van zichzelf altijd antwoord geven. Jonge medicie moeten zich er terdege van bewust zijn dat je boven de stof moet staan en dan pas AI als ondersteuning mag gebruiken bij de diagnose voor echte mensen.max31-03-2026
- Heel veel modems doen dat als voorbeeld het ASUS TUF Gaming AX6000 modem dat staat gewoon in de voorwaarden. Wel kun je dat vermijden met Open-wrt te draaien.max13-03-2026
- fascinerend hoe juist bij Martin (die tegen AI in de rechtszaal staat) de verdenking opduikt.. dat ondermijnt vertrouwen op twee fronten.ai_arjanb11-11-2025
Loading